Inside the Classroom: My Experience Teaching Advanced Data Science with Python

I joined Xebia as a trainer about a year ago. I was a data scientist before this, but I had no idea how much I’d learn by teaching. Since then, I’ve delivered over 6 Advanced Data Science with Python courses, constantly iterating and improving the material based on what I see students struggle with. Here’s what I’ve learned, and what you can expect if you join us.
After every session, I notice the same pattern. Many data scientists (with 0-3 years experience) are comfortable with the basics. They can load data with Pandas, train a model with scikit-learn, and get a result using .fit() and .predict(). But then they hit a wall. Their projects become messy. Their results aren’t easily reproducible. They struggle with real-world problems like imbalanced data or building custom logic for their specific business needs.
This is exactly why you will created this course. It’s not about learning data science from zero but it’s about learning how to do it professionally and giving you the structure and best practices to build robust, reliable, and powerful machine learning solutions.
So here’s my perspective from inside the classroom.
The three key takeaways from the training
The course does three main things to turn your chaotic notebooks into professional workflows. Let me walk you through what you can expect.
You’ll build clean, reproducible scikit-learn pipelines
What: You will move you beyond messy, one-off notebook cells. You’ll learn how to organize your entire machine learning workflow, from data cleaning and feature engineering to model training, into a single, elegant Pipeline object.
Why: Reproducibility is the key to professional data science. Pipelines make your work easy to understand, reuse, and debug. It’s a game-changer for collaboration and putting models into production.
How: You will build them step-by-step, showing you how to chain together transformers and an estimator into a single, powerful tool.
You will learn how to structure your code into key steps:
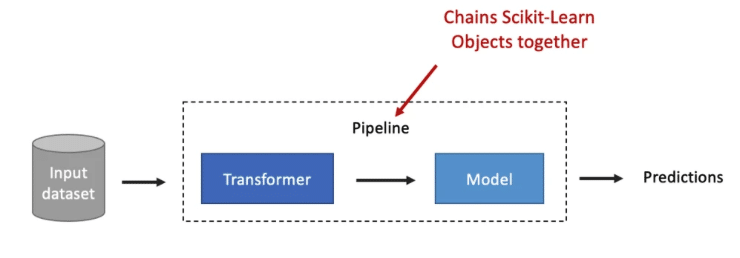
Instead of scattered notebook cells, everything flows through one organized pipeline.
You will master advanced techniques and write custom solutions
What: You will go far beyond just checking a model’s accuracy and using off-the-shelf tools. You’ll master proper validation techniques like cross-validation and also learn to write your own custom transformers and estimators that integrate perfectly with scikit-learn.
Why: Real business problems are messy. A single accuracy score can be misleading, and scikit-learn can’t solve every problem out of the box. Your business has unique logic and limitations. These advanced skills let you build solutions tailored to your specific needs and validate them properly.
How: You will run hands-on exercises covering model selection, cross-validation, and best practices for challenges like imbalanced datasets. You will also introduced object-oriented programming in a practical way, teaching you the simple class structure scikit-learn uses so you can start building your own components.
Here’s a practical example of custom components you’ll build:
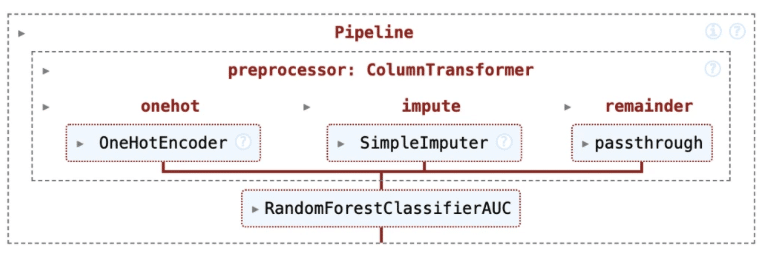
RandomForestClassifierAUC is our custom model that uses AUC instead of accuracy as the scoring metric.
You will apply your skills in an intensive hackathon
What: At the end of each day, you will run a hands-on hackathon where you apply all the concepts you’ve learned to a challenging problem which will make you to struggle but also really understand the WHYs behind!
Why: You learn best by doing. The hackathons are designed to take the theory and turn it into practical skill. This is where the concepts really “click”.
How: These are collaborative, fast-paced sessions where you’ll work with your peers to build a complete solution from start to finish.
A Confession from a Trainer
My favorite moment in this training comes on Day 2. It’s the “aha!” moment when a student writes their first custom transformer, integrates it into a pipeline, and sees it work perfectly. That’s my favorite part because it’s exactly what I felt when I learned these skills as a data scientist.
It’s the moment you realize you are no longer just using a library; you are extending it to fit their own needs. Seeing students have those kind of breakthroughs is the most rewarding part of my job.
And that’s the goal of Xebia! We want you to leave this course feeling empowered, with the skills and confidence to tackle more complex data science challenges than ever before.
Ready to transform your messy data science into professional workflows?
Join us for two days of deep-diving into data science, machine learning, and Python. You’ll leave with better code, more powerful models, and a framework for improving all your future projects.